在 Google Colab 上 Debug 的正确方式
Colaboratory(简称 Colab)是 Google 推出的免费、在线、具有 GPU 的 JupyterLab 环境,它的底层是一个虚拟的 Linux 系统,所以你在里面执行 Linux 命令也是没有问题的。
我的本科毕业设计是做的深度学习相关的内容,但自己笔记本电脑里的 GTX 950M(2G)显卡一跑代码就爆显存,所以不夸张地说我是全靠 Colab 才顺利毕业。
扯远了,本文主要是测试一下 Colab 调试代码的方法,结论就是对于结构比较复杂的代码 Colab 并不能很好地完成调试。
0x00 一些 Colab 使用心得
Colab 的优点
- 环境配置简单。深度学习相关的很多软件包都是预装好的,省事省时;
- 网络环境通畅。数据中心带宽大,下载数据集嗖嗖的;
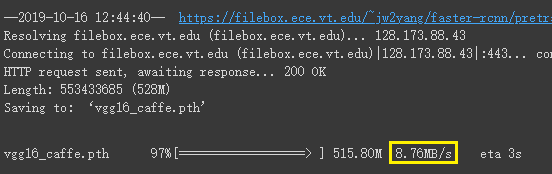
下载预训练模型的速度
- GPU 够用。原来白天能分到 Telsa T4,现在白天也只有 Tesla K80 了,但起码 11.4GB 的显存是实打实的;
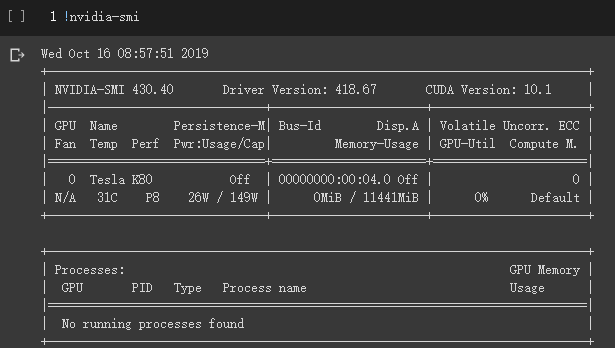
在 code cell 中使用 !nvidia-smi 命令查看 GPU 信息
- 支持 bash 命令。bash 命令想要在 code cell 里执行只需每行前加
!就可以了;
Colab 环境中 /bin 目录的内容
- 支持在线修改。对于大型工程,其代码必然分散在项目的各个文件夹里,以前想修改文件内容需要下载到本地修改然后再上传,十分繁琐。2019 年 10 月 4 日 Colab 支持了从文件树双击打开、修改文件。
@GoogleColab 的推文截图
- 更多 Colab 特性可以查看 Google 的说明文档
Colab 的缺点
- 资源自动回收。据说是运行 12 小时后自动回收所有资源(另外实际经验是如果浏览器与 Colab 的连接不幸中断数小时也会触发回收),GPU 需要重新申请是其次,重要的是保存运行结果的临时硬盘空间也会被回收掉。所以可以考虑把 Google Drive 挂载上去然后结果直接存在里边,这就会带来下面第二个缺点;
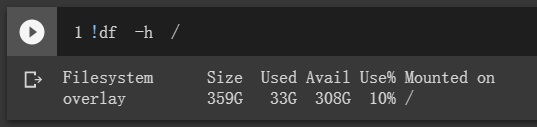
Colab 临时硬盘有 359 GB
- 与 Google Drive 不能无缝整合。同一份代码,直接在 Colab 临时硬盘空间运行与克隆到被挂载到 Colab 的 Google Drive 运行有明显可感的降速,瓶颈可能是 Google Drive 本身存储介质的 I/O 性能;
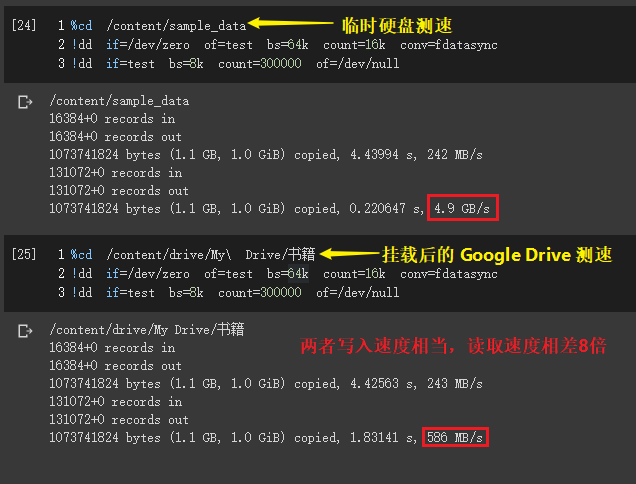
Colab 临时硬盘与挂载的 Google Drive 在 Colab 中读写速度对比
- 不易使用图形化监测工具如 Tensorboard / Visdom 。没有官方解决方案,必须依靠奇技淫巧——换用 TensorBoardX、给 Visdom 套上反向代理。
0x01 Jupyter 101:magic commands
所谓 magic commands 就是在 Jupyter 代码块中以 % 或者 %% 作为行首的特殊命令。而 bash 命令需要使用 ! 作为行首。
%开头——行命令。只对命令所在的行有效%%开头——单元命令。必须出现在单元的第一行,对整个单元的代码进行处理
在代码块中输入 %lsmagic 然后执行会输出关于各个命令的说明,在魔法命令之后紧跟 ? 可以查看该命令的详细说明。
%cd进入目录命令(改变本代码块的 当前工作目录 并在之后的代码块中保持,而!cd仅对当前行有效)%load_ext根据模块名载入模块(可以用于在本代码块的输出中载入 tensorboardX)%magic显示所有魔法命令的详细文档%whos打印所有变量及其类型和值%xdel删除指定变量%set_env <var> <val>设定环境变量的值%psource打印对象的源代码%pinfo打印对象的详细信息%pfile打印对象的定义%%latex以 $LaTeX$ 格式渲染 cell%run script.py在ipython中执行一个外部的脚本文件%%python3以 Python 3 执行 cell(Python 2 同理)%hist查询输入的历史%writefile [-a] filename把 cell 的内容写/追加入文件(别名 file)%env显示所有/特定/修改系统环境变量%reset清空 namespace%load加载代码到前端(可以是链接)
http://nbviewer.jupyter.org/github/supergis/git_notebook/blob/master/pystart/jupyter_magics.ipynb
0x02 使用 ipdb 进行调试
常规的 Python 交互式 debug 工具是 pdb,它可以让我们 单步 调试;IPython 改进版的 pdb 被称为 ipdb 。
在 IPython 内核环境中最方便的调用 ipdb 的方法是使用魔法命令 %debug。如果是在遇到异常之后立刻运行 %debug 则会自动在异常位置打开一个交互式调试提示符,该 ipdb 调试提示符可以实现检查当前栈、变量或是使用 Python 命令。以下是简单示范:
def func1(a, b):
return a / b
def func2(x):
a = x
b = x - 1
return func1(a, b)当调用 func2(1) 时,将抛出异常:
Traceback (most recent call last):
File "<ipython-input-4-b2e110f6fc8f>", line 1, in <module>
func2(1)
1 frames
File "<ipython-input-1-d849e34d61fb>", line 7, in func2
return func1(a, b)
File "<ipython-input-1-d849e34d61fb>", line 2, in func1
return a / b
ZeroDivisionError: division by zero使用 ipdb 调试:
> <ipython-input-1-d849e34d61fb>(2)func1()
1 def func1(a, b):
----> 2 return a / b
3
ipdb> up
> <ipython-input-1-d849e34d61fb>(7)func2()
5 a = x
6 b = x - 1
----> 7 return func1(a, b)
ipdb> print(x)
1
ipdb> up
> <ipython-input-6-b2e110f6fc8f>(1)<module>()
----> 1 func2(1)
ipdb> down
> <ipython-input-1-d849e34d61fb>(7)func2()
5 a = x
6 b = x - 1
----> 7 return func1(a, b)
ipdb> quit| Command | Description |
|---|---|
list | 显示当前行的上下5行 |
up | 步退 |
down | 步进 |
n(ext) | 当前文件中下一步 Go to the next step of the program |
s(tep) | 下一步,如果有就进入子函数(Step into a subroutine) |
r(eturn) | 退出子函数(Return out of a subroutine) |
<enter> | 重复前条命令 |
p(rint) | 打印指定变量值 |
c(ontinue) | 退出调试器,继续运行程序 |
q(uit) | 退出调试器,终止程序 |
h(elp) | 显示所有命令/指定命令的帮助 |
b LINE | 在指定行设置断点 |
上述例子调用 ipdb 发生在产生异常之后,目的是为了修改程序中的错误;如果我们的程序运行良好,想通过调试观察函数调用,就不能再用简单的行魔法命令 %debug 而是为其加上参数甚至变成单元命令。
%pdb与%debug用法的不同(总结自%debug?)
如果想在每次 产生异常后 让 IPython 自动进入 交互式调试提示符——
%pdb on或者%pdb 1如果想在每次产生异常后 手动进入 交互式调试提示符——不加参数地使用
%debug如果想无论有没有异常都激活交互式调试提示符——带参数地使用
%debug
如何带参数地使用 %debug
失败的尝试
%debug –breakpoint <FILE>:<LINE>结果:无法调起 ipdb 交互式调试提示符。只会显示一个不响应 ipdb 命令的输入框。Jupyter code cell and output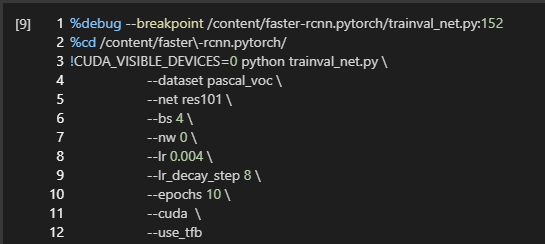
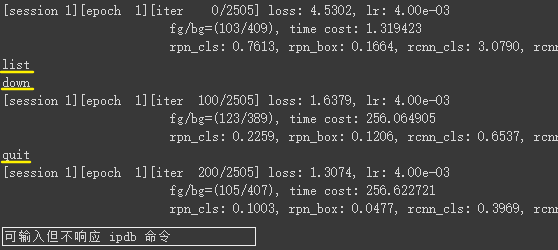
%%debug –breakpoint <FILE>:<LINE>结果:无法运行到标记的断点。Python 处理基本调试器函数的 bdb 模块出现异常,未搜到解决方法。尝试不加-b参数异常不变。Jupyter code cell and output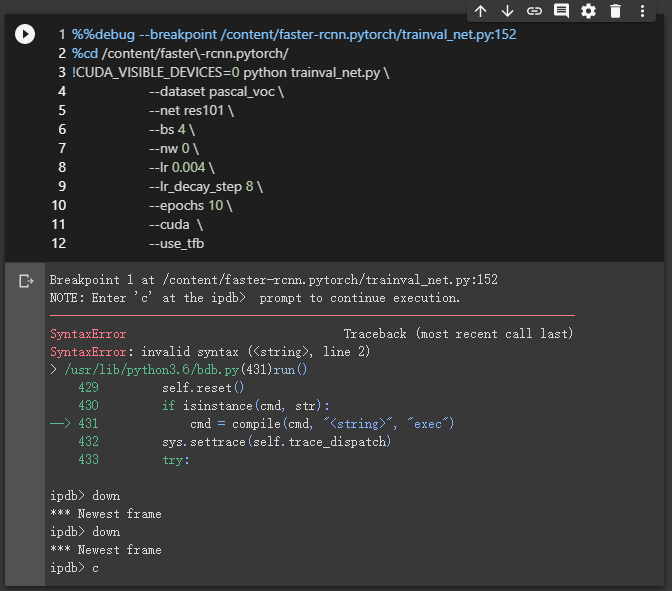
可行方式
手动在程序中设置断点。但调试过程复杂低效。首先要先在 Jupyter 环境安装 ipdb:
# 安装 ipdb
# P.S. 按 https://stackoverflow.com/a/32409822/8178171 的讨论也可以使用 pdb,那么下面加断点时也要改成 pdb
!pip3 install ipdb然后在代码中加入断点:
# 源程序想设置断点处:添加此行
import ipdb; ipdb.set_trace()实际效果如下:
